linguishi/chinese_sentiment
TensorFlow 1.13 sentiment analysis that still trains in minutes
A no-frills Chinese text-classification benchmark comparing CNN and BI-LSTM on a 4,000-sample hotel-review corpus.
Not currently ranked — collecting fresh signals.
star history
What it does
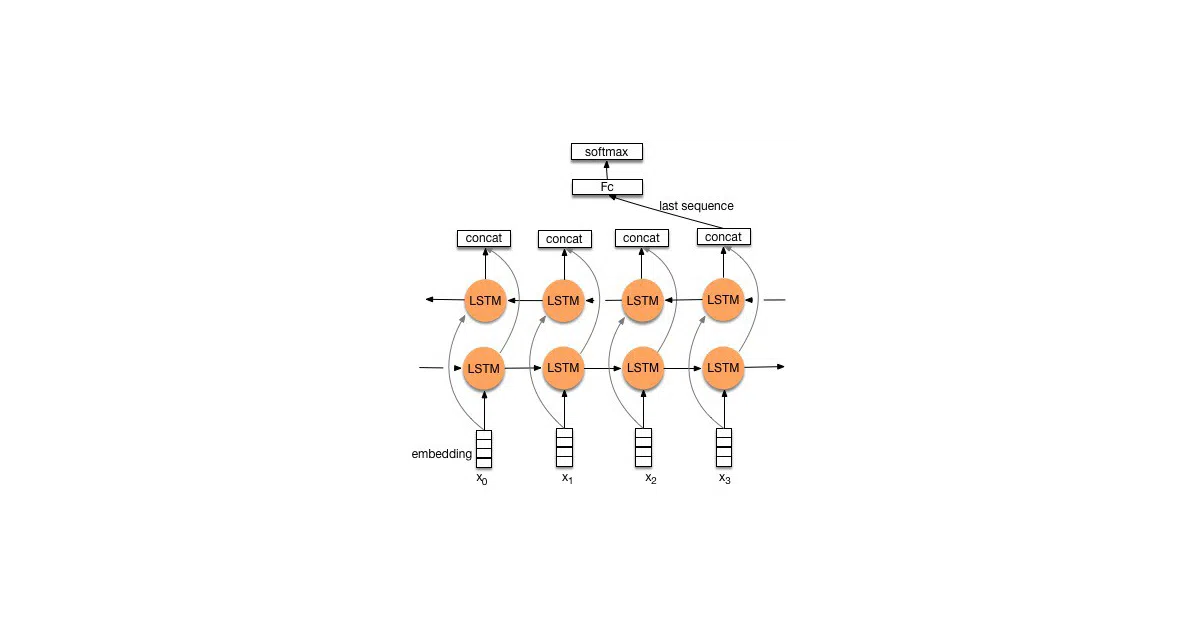
Trains two classic neural-network architectures—CNN with multiple filter widths and BI-LSTM—to classify Chinese hotel reviews as positive or negative. The repo includes the full data-pipeline: GB2312-to-UTF-8 conversion, jieba tokenization, vocabulary indexing, and pruning a large pretrained word-vector file down to only the tokens you actually need.
The interesting bit
The author treats this as a generic text-classification framework, not just sentiment analysis. Swap in your own corpus (same tab-separated format) and the same scripts build vocabularies, embeddings, and serving graphs automatically. It is essentially well-organized glue code around 2018-era TensorFlow Estimators.
Key highlights
- CNN trains in ~2 minutes, BI-LSTM in ~5 minutes on a GTX 1060
- Both models hit ~0.89 F1 on an 800-sample validation set (400 POS / 400 NEG)
- Includes a pretrained
saved_modelfor BI-LSTM so you can test without training - Uses external Chinese word vectors (Zhihu corpus) via the
chinese-word-vectorsproject - Serving script (
serve.py) demonstrates loading the exported Estimator graph for inference
Caveats
- Locked to Python 3.6 and TensorFlow 1.13; the author notes other environments are untested
- Word vectors must be downloaded manually from Baidu Pan, which is a friction point for non-China users
- The README contains a typo (“号回率” for 召回率) and the serving section mislabels the task as “entity recognition”
Verdict
Worth a look if you need a minimal, working Chinese-text-classification baseline in legacy TensorFlow, or if you are teaching the classic CNN-for-text pipeline. Skip it if you want modern transformers, multilingual models, or anything that runs on TF 2.x without surgery.
Frequently asked
- What is linguishi/chinese_sentiment?
- A no-frills Chinese text-classification benchmark comparing CNN and BI-LSTM on a 4,000-sample hotel-review corpus.
- Is chinese_sentiment open source?
- Yes — linguishi/chinese_sentiment is an open-source project tracked on heatdrop.
- What language is chinese_sentiment written in?
- linguishi/chinese_sentiment is primarily written in Python.
- How popular is chinese_sentiment?
- linguishi/chinese_sentiment has 1.1k stars on GitHub.
- Where can I find chinese_sentiment?
- linguishi/chinese_sentiment is on GitHub at https://github.com/linguishi/chinese_sentiment.