kubernetes-retired/kube-batch
Kubernetes' retired batch scheduler that outlived its own repo
A batch scheduler for AI/ML and HPC workloads that graduated into Volcano and Kubeflow, then got archived.
Not currently ranked — collecting fresh signals.
star history
What it does
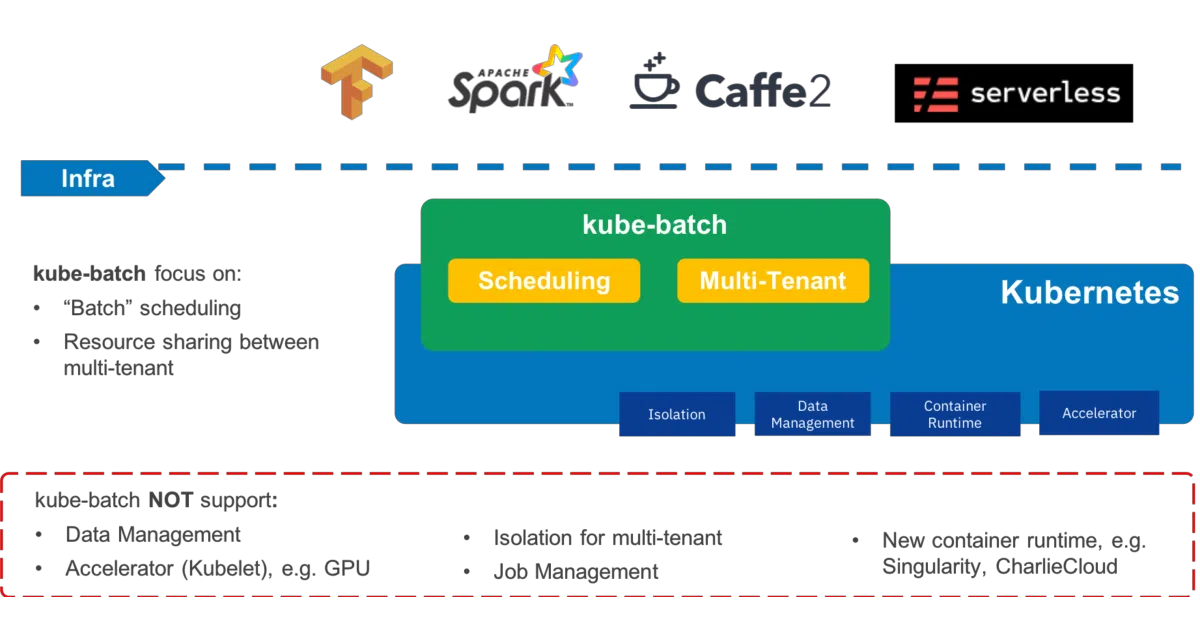
kube-batch is a batch scheduler for Kubernetes, designed for high-performance workloads like AI/ML, Big Data, and HPC. It sits alongside the default scheduler to handle gang scheduling, queueing, and resource sharing for jobs that need to run as coordinated groups rather than scattered pods.
The interesting bit
The project is officially retired by Kubernetes, yet its DNA lives on: both Kubeflow and Volcano — two of the most active batch-scheduling ecosystems in Kubernetes — started here. It’s a rare case of a project that succeeded itself into obsolescence.
Key highlights
- Born from “a decade and a half of experience” running batch workloads at scale (the README’s claim, not independently verifiable)
- Adopted by Baidu, TuSimple, Vivo, and others before retirement
- Explicitly scoped: handles core scheduling mechanisms, leaves “out-of-scope” parts to other projects
- Community channel still points to active Kubernetes SIG Scheduling
Caveats
- Repository is retired/archived; no ongoing development
- README is thin on technical specifics — no benchmarks, no detailed feature list, no comparison to default scheduler
- Architecture diagram exists but isn’t explained in text
Verdict
Worth studying if you’re building a Kubernetes scheduler or tracing the lineage of Volcano/Kubeflow. Skip it if you need something production-ready today — use Volcano instead.
Frequently asked
- What is kubernetes-retired/kube-batch?
- A batch scheduler for AI/ML and HPC workloads that graduated into Volcano and Kubeflow, then got archived.
- Is kube-batch open source?
- Yes — kubernetes-retired/kube-batch is open source, released under the Apache-2.0 license.
- What language is kube-batch written in?
- kubernetes-retired/kube-batch is primarily written in Go.
- How popular is kube-batch?
- kubernetes-retired/kube-batch has 1.1k stars on GitHub.
- Where can I find kube-batch?
- kubernetes-retired/kube-batch is on GitHub at https://github.com/kubernetes-retired/kube-batch.