jeinlee1991/chinese-llm-benchmark
Benchmarking Chinese LLMs like civil-service exam candidates
ReLE ranks hundreds of Chinese LLMs across 300 specialized domains—from dental licensing to classical poetry—and archives over two million of their failures for public analysis.
★6.3k stars LLMOps · Eval
Not currently ranked — collecting fresh signals.
star history
What it does
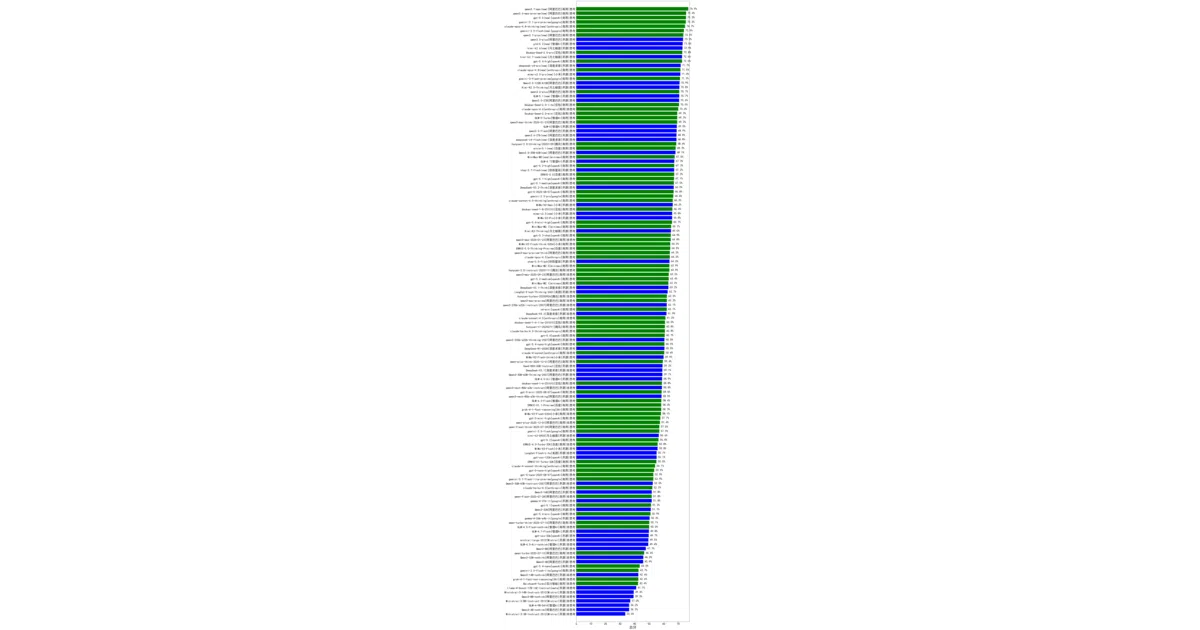
ReLE (Really Reliable Live Evaluation) is a live, continuously updated ranking system for Chinese large language models. It evaluates hundreds of commercial and open-source models across seven verticals—education, medicine, finance, law, reasoning, language, and agentic tool use—drilling down into roughly 300 sub-domains such as high-school Chinese, dental licensing, and civil-service exams. Beyond the leaderboard, the project curates a structured defect library of over two million failure cases that researchers can mine for targeted error analysis.
The interesting bit
Instead of treating multilingual ability as a single checkbox, ReLE treats it as a stack of specialized provincial exams. The maintainers also offer free private evaluations via WeChat, effectively turning the repository into a hybrid public dashboard and bespoke testing lab.
Key highlights
- Evaluates ~300 sub-domains across seven verticals, from mental health to securities law.
- Maintains a defect library of 2M+ model failures for downstream research.
- Tracks both commercial APIs and open-source weights in unified ranking tables.
- Publishes an arXiv technical report on diagnosing “capability anisotropy” in Chinese LLMs.
- Offers free benchmarking as a service for private models.
Caveats
- Many listed categories remain marked TODO in the source (e.g., middle-school olympiad, spatial reasoning, traditional/simplified Chinese conversion), so coverage is still incomplete.
Verdict
Worth bookmarking if you are building or selecting Chinese-facing LLMs and need domain-specific signal beyond generic MMLU scores. Skip it if you are only interested in English-centric capabilities or ready-to-use inference code—the repo is pure evaluation infrastructure.
Frequently asked
- What is jeinlee1991/chinese-llm-benchmark?
- ReLE ranks hundreds of Chinese LLMs across 300 specialized domains—from dental licensing to classical poetry—and archives over two million of their failures for public analysis.
- Is chinese-llm-benchmark open source?
- Yes — jeinlee1991/chinese-llm-benchmark is an open-source project tracked on heatdrop.
- How popular is chinese-llm-benchmark?
- jeinlee1991/chinese-llm-benchmark has 6.3k stars on GitHub.
- Where can I find chinese-llm-benchmark?
- jeinlee1991/chinese-llm-benchmark is on GitHub at https://github.com/jeinlee1991/chinese-llm-benchmark.