jaywalnut310/vits
Single-stage speech synthesis with ground-truth ambitions
VITS exists to prove that a single-stage, parallel text-to-speech model can sound as natural as two-stage systems while letting the same text vary in pitch and rhythm.
Not currently ranked — collecting fresh signals.
star history
What it does
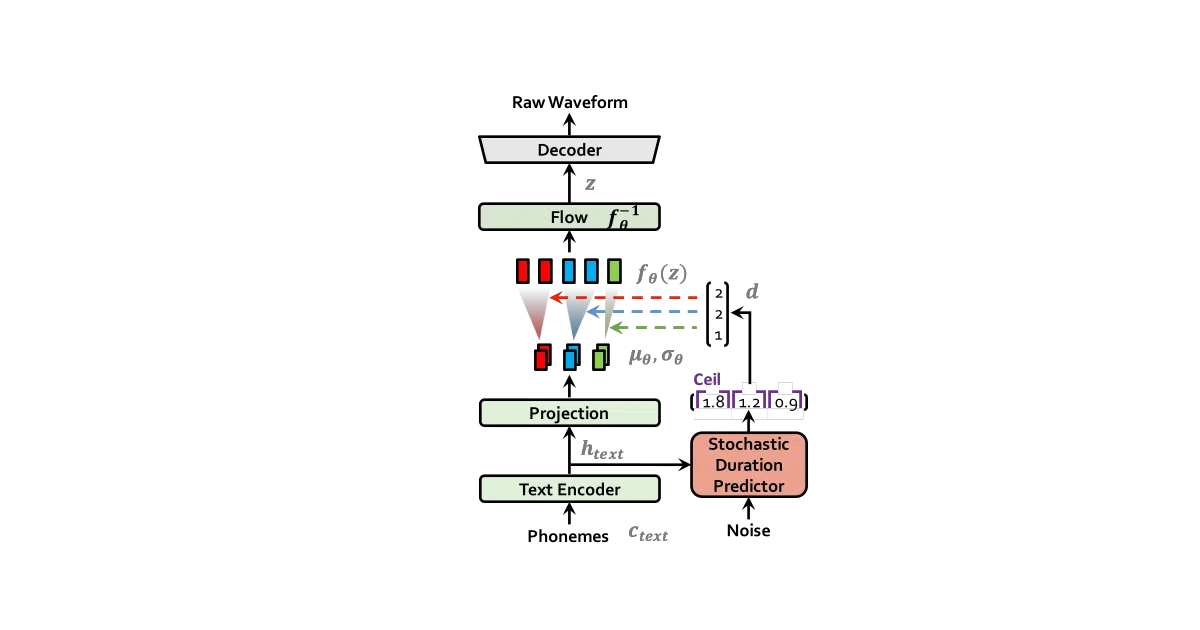
VITS is an end-to-end text-to-speech system that generates raw audio from text in a single pass, bypassing the usual intermediate spectrogram or vocoder stages. The authors report that it outperforms publicly available two-stage TTS systems in subjective mean-opinion-score (MOS) tests on LJ Speech and reaches parity with ground-truth recordings. The repository ships with pretrained models, a Colab demo, and an inference.ipynb notebook.
The interesting bit Instead of a rigid text-to-audio mapping, VITS models the problem as conditional generation: it uses variational inference with normalizing flows, adversarial training, and a stochastic duration predictor so the same sentence can emerge with different pitches and rhythms. It is essentially a VAE that learned to improvise.
Key highlights
- Single-stage, parallel generation: text goes in, raw audio comes out without separate vocoder or mel-spectrogram steps.
- Stochastic duration predictor and latent uncertainty explicitly model the one-to-many relationship between text and speech.
- Authors report MOS scores on LJ Speech comparable to ground truth, outperforming other public TTS systems.
- Supports both single-speaker (LJ Speech) and multi-speaker (VCTK) setups.
- Pretrained models and an interactive Colab notebook are available.
Caveats
- Custom datasets require building a Cython extension for monotonic alignment search and running your own phoneme preprocessing.
- Documentation and configuration are tightly coupled to LJ Speech and VCTK; new voices or languages need manual wiring.
Verdict A solid starting point for researchers or hackers who want a competitive end-to-end TTS baseline with pretrained weights. Look elsewhere if you need a plug-and-play SaaS API or broad multilingual support.
Frequently asked
- What is jaywalnut310/vits?
- VITS exists to prove that a single-stage, parallel text-to-speech model can sound as natural as two-stage systems while letting the same text vary in pitch and rhythm.
- Is vits open source?
- Yes — jaywalnut310/vits is open source, released under the MIT license.
- What language is vits written in?
- jaywalnut310/vits is primarily written in Python.
- How popular is vits?
- jaywalnut310/vits has 7.9k stars on GitHub.
- Where can I find vits?
- jaywalnut310/vits is on GitHub at https://github.com/jaywalnut310/vits.