google-deepmind/bsuite
A standardized stress-test for reinforcement learning agents
bsuite replaces ad-hoc RL benchmarking with a curated battery of small, fast experiments that diagnose specific algorithmic weaknesses.
Not currently ranked — collecting fresh signals.
star history
What it does
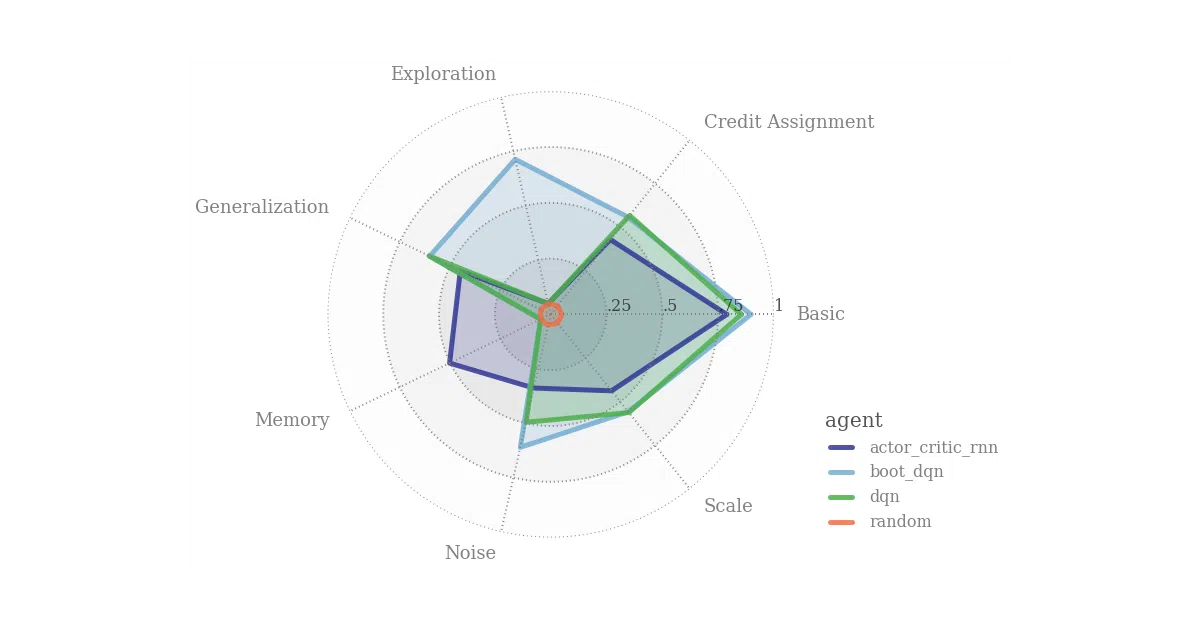
bsuite is a collection of lightweight, carefully-designed RL environments that test specific capabilities—generalization, exploration, credit assignment, scaling—rather than raw score on a single hard game. Each experiment comes with predefined difficulty sweeps, automatic logging, and a shared analysis notebook. You load an environment by ID (e.g., 'deep_sea/7'), run your agent, and the built-in logging spits out data ready for the provided Jupyter/Colab analysis pipeline.
The interesting bit
The project treats evaluation as infrastructure, not afterthought. It includes a one-page LaTeX report generator for conference appendices, plus a GCP runner script that spins up a 64-core instance, runs the full sweep, copies results back, and shuts itself down. The environments are deliberately small-network-CPU-friendly, so you can iterate quickly without GPU babysitting.
Key highlights
- Environments grouped by tags like
basicandscaleviasweep.TAGS - Automatic CSV or terminal logging through wrapper functions; custom loggers are straightforward
- OpenAI Gym compatibility via
GymFromDMEnvwrapper - Pre-built baselines (DQN, etc.) with parallel run scripts; full sweep completes overnight on a 12-core machine
- Ready-made Colab notebook for analysis and visualization
- Conference-formatted PDF report generation (NeurIPS-style included)
Caveats
- Python support officially tested only on 3.6 and 3.7, which are now EOL
- SQLite logger was dropped in newer versions; the README says to “contact us” if you want it reinstated
- Gym and Dopamine baseline dependencies are optional extras, not installed by default
Verdict
Researchers building or tuning RL algorithms who need rigorous, comparable diagnostics across multiple capabilities should grab this. If you’re just training a single agent on a single environment and don’t care about systematic behavioral analysis, it’s overkill.
Frequently asked
- What is google-deepmind/bsuite?
- bsuite replaces ad-hoc RL benchmarking with a curated battery of small, fast experiments that diagnose specific algorithmic weaknesses.
- Is bsuite open source?
- Yes — google-deepmind/bsuite is open source, released under the Apache-2.0 license.
- What language is bsuite written in?
- google-deepmind/bsuite is primarily written in Python.
- How popular is bsuite?
- google-deepmind/bsuite has 1.5k stars on GitHub.
- Where can I find bsuite?
- google-deepmind/bsuite is on GitHub at https://github.com/google-deepmind/bsuite.