fishaudio/fish-speech
A TTS model that treats [whisper] and [shout] as first-class tokens
Fish Speech S2 Pro is a 4B-parameter dual-autoregressive TTS model that treats inline emotional tags like `[whisper]` as native tokens to synthesize speech in over 80 languages.
Velocity · 7d
+11
★ / day
Trend
↘cooling
star history
What it does
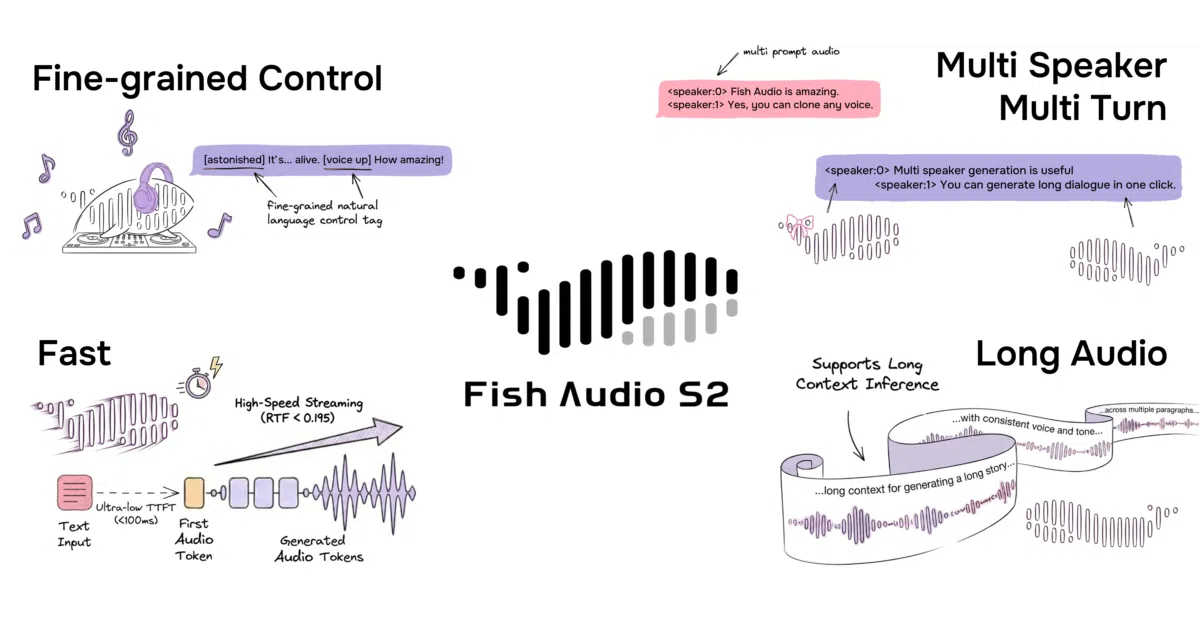
Fish Speech S2 Pro converts text into natural-sounding speech across more than 80 languages. It supports voice cloning from 10–30 seconds of reference audio, multi-speaker dialogue via speaker ID tokens, and multi-turn generation that uses prior context to improve expressiveness. The repository provides model weights, benchmark data, and integration pointers for SGLang and vLLM Omni inference servers.
The interesting bit
Instead of treating emotion as a global setting, S2 Pro parses inline natural-language tags—over 15,000 unique descriptors such as [laughing], [inhale], or [pitch up]—at sub-word granularity. A master-slave Dual-AR architecture handles semantics with a 4B-parameter slow autoregressive model while a 400M-parameter fast model fills in nine residual audio codebooks, a design that lets it borrow standard LLM serving optimizations like Paged KV Cache and Continuous Batching.
Key highlights
- The project reports Seed-TTS Eval word-error rates of 0.54% (Chinese) and 0.99% (English), which it presents as the lowest among evaluated open- and closed-source systems, plus an 81.88% win rate on EmergentTTS-Eval.
- Reinforcement learning alignment via Group Relative Policy Optimization uses the same model suite as reward models to judge semantic accuracy, instruction adherence, and timbre similarity.
- On an NVIDIA H200, the project cites a real-time factor of 0.195 and time-to-first-audio of roughly 100 ms when served through SGLang.
- Native multi-speaker generation assigns
<|speaker:i|>tokens from a single mixed reference clip, eliminating the need to upload separate audio per voice.
Caveats
- Weights and code are released under a custom Fish Audio Research License rather than a standard open-source license; the authors explicitly warn they will take action against violations.
- The published latency and throughput figures were measured on an H200 GPU with SGLang; performance on consumer hardware is not characterized in the README.
Verdict
Worth exploring if you need research-grade, multilingual voice synthesis with fine-grained emotional control and can accept a restrictive license. Skip it if you want a lightweight, permissively licensed TTS utility.
Frequently asked
- What is fishaudio/fish-speech?
- Fish Speech S2 Pro is a 4B-parameter dual-autoregressive TTS model that treats inline emotional tags like `[whisper]` as native tokens to synthesize speech in over 80 languages.
- Is fish-speech open source?
- Yes — fishaudio/fish-speech is an open-source project tracked on heatdrop.
- What language is fish-speech written in?
- fishaudio/fish-speech is primarily written in Python.
- How popular is fish-speech?
- fishaudio/fish-speech has 31.4k stars on GitHub and is currently cooling off.
- Where can I find fish-speech?
- fishaudio/fish-speech is on GitHub at https://github.com/fishaudio/fish-speech.