facebookresearch/vjepa2
Meta's video model learns physics by watching YouTube, then picks up cups
Self-supervised video encoders that bootstrap world understanding from unlabeled internet footage, with a surprising second act in robot manipulation.
Velocity · 7d
+4.3
★ / day
Trend
→steady
star history
What it does
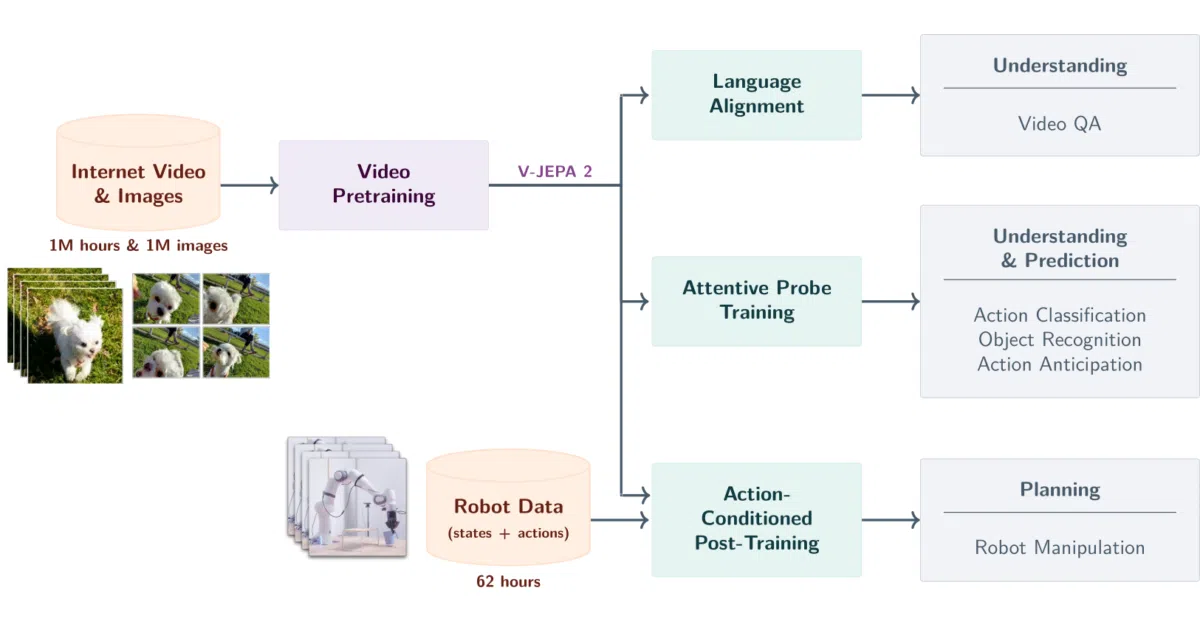
V-JEPA 2 trains video encoders without human labels by masking chunks of video and forcing the model to predict latent features in the hidden regions. The newer V-JEPA 2.1 variant refines this with dense predictive loss applied to all tokens, deep self-supervision at multiple encoder layers, and multi-modal tokenizers. Both versions ship as PyTorch checkpoints ranging from 80M to 2B parameters, loadable via PyTorch Hub or HuggingFace.
The interesting bit
The project has two personalities. First: a general video understanding engine that tops benchmarks on action anticipation (EK100) and video QA. Second, and more unexpected: V-JEPA 2-AC, a world model fine-tuned on scant robot trajectory data that plans manipulation tasks from image goals alone. On a Franka arm with monocular RGB, it outperforms Octo and Cosmos on grasping and pick-and-place—despite no environment-specific training or calibration. The README’s benchmark table shows VJEPA 2-AC hitting 60% cup grasp versus Octo’s 10% and Cosmos’s 0%.
Key highlights
- Self-supervised pretraining on internet-scale video; no labeled datasets required for the base model
- V-JEPA 2.1 explicitly optimizes for temporally consistent dense features, not just global video embeddings
- Action-conditioned variant (2-AC) transfers to real robot arms with minimal post-training data
- Checkpoints available at four scales (ViT-B through ViT-G), plus attentive probes for SSv2, Diving48, and EPIC-KITCHENS-100
- Supports both PyTorch Hub and HuggingFace
AutoModelloading patterns
Caveats
- The V-JEPA 2.1 paper link is listed as arXiv “TODO”—not yet published
- Robot results, while favorable against named baselines, are from a single arm setup with limited object types (cups, boxes)
- The 2B-parameter ViT-G/16 model demands significant compute; the README “strongly recommends” CUDA
Verdict
Worth studying if you’re in video representation learning, embodied AI, or curious whether self-supervised pretraining can finally bridge the sim-to-real gap without sim. Skip if you need a production-ready robot stack today—the manipulation results are promising but narrow.
Frequently asked
- What is facebookresearch/vjepa2?
- Self-supervised video encoders that bootstrap world understanding from unlabeled internet footage, with a surprising second act in robot manipulation.
- Is vjepa2 open source?
- Yes — facebookresearch/vjepa2 is open source, released under the MIT license.
- What language is vjepa2 written in?
- facebookresearch/vjepa2 is primarily written in Python.
- How popular is vjepa2?
- facebookresearch/vjepa2 has 4.4k stars on GitHub and is currently holding steady.
- Where can I find vjepa2?
- facebookresearch/vjepa2 is on GitHub at https://github.com/facebookresearch/vjepa2.