facebookresearch/sam-audio
Meta’s SAM for audio isolates sounds with text, video, or timestamps
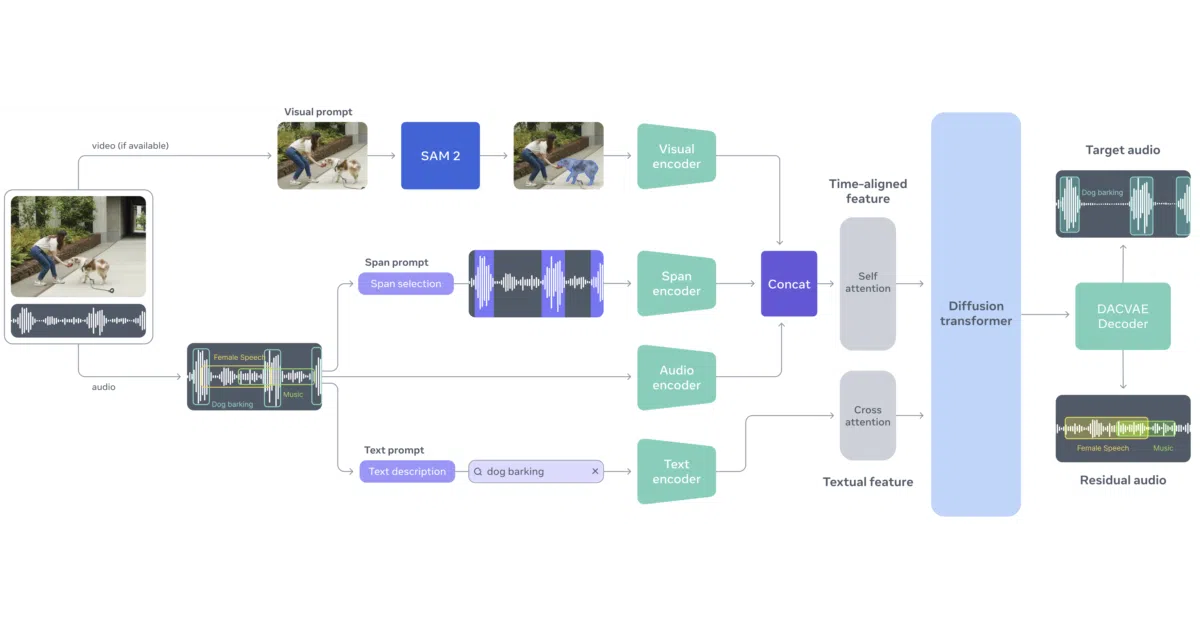
SAM-Audio is a foundation model that pulls a single sound out of a messy audio mix when you prompt it with natural language, a masked video frame, or a specific time span.
Not currently ranked — collecting fresh signals.
star history
What it does
SAM-Audio is Meta’s attempt to do for sound what the original SAM did for pixels: isolate a specific target from everything else. You feed it a mixed audio clip and a prompt—text like “car honking,” a masked region of a video frame, or an exact time span—and it returns two tracks: the isolated target and the residual background. It is built on top of a Perception-Encoder Audio-Visual backbone and ships in three sizes, plus specialized variants tuned for visual prompting.
The interesting bit
The model does not just perform one-shot separation; it can generate multiple candidate isolations and rerank them using an internal “Judge” model (and optionally CLAP or ImageBind) to score precision, recall, and faithfulness. It also predicts temporal spans automatically from text descriptions, so you do not have to manually timestamp transient events like a door slam.
Key highlights
- Prompts via text, masked video frames, or explicit time anchors.
- Optional span prediction infers when a sound occurs from its description alone.
- Built-in reranking generates up to k candidates and selects the best via the Judge model or embedding similarity metrics.
- Releases include
sam-audio-largeand a-tvvariant optimized for visual prompting correctness. - Checkpoints are gated on Hugging Face and require authenticated access.
Caveats
- Checkpoints are gated on Hugging Face and require authenticated access.
- A CUDA-compatible GPU is recommended, and the best quality settings trade latency and memory for better results.
- The evaluation scores in the README are subjective ratings, not objective reconstruction metrics like SDR.
Verdict
Audio researchers and engineers building content-aware separation or video-editing tools should look here; if you need lightweight, real-time source separation on a CPU, this is probably too heavy.
Frequently asked
- What is facebookresearch/sam-audio?
- SAM-Audio is a foundation model that pulls a single sound out of a messy audio mix when you prompt it with natural language, a masked video frame, or a specific time span.
- Is sam-audio open source?
- Yes — facebookresearch/sam-audio is an open-source project tracked on heatdrop.
- What language is sam-audio written in?
- facebookresearch/sam-audio is primarily written in Python.
- How popular is sam-audio?
- facebookresearch/sam-audio has 3.6k stars on GitHub.
- Where can I find sam-audio?
- facebookresearch/sam-audio is on GitHub at https://github.com/facebookresearch/sam-audio.