databricks/mlops-stacks
Databricks' cookie-cutter for ML projects that won't embarrass you in prod
A project template that wires up training pipelines, batch inference, and CI/CD before you write your first line of model code.
Not currently ranked — collecting fresh signals.
star history
What it does
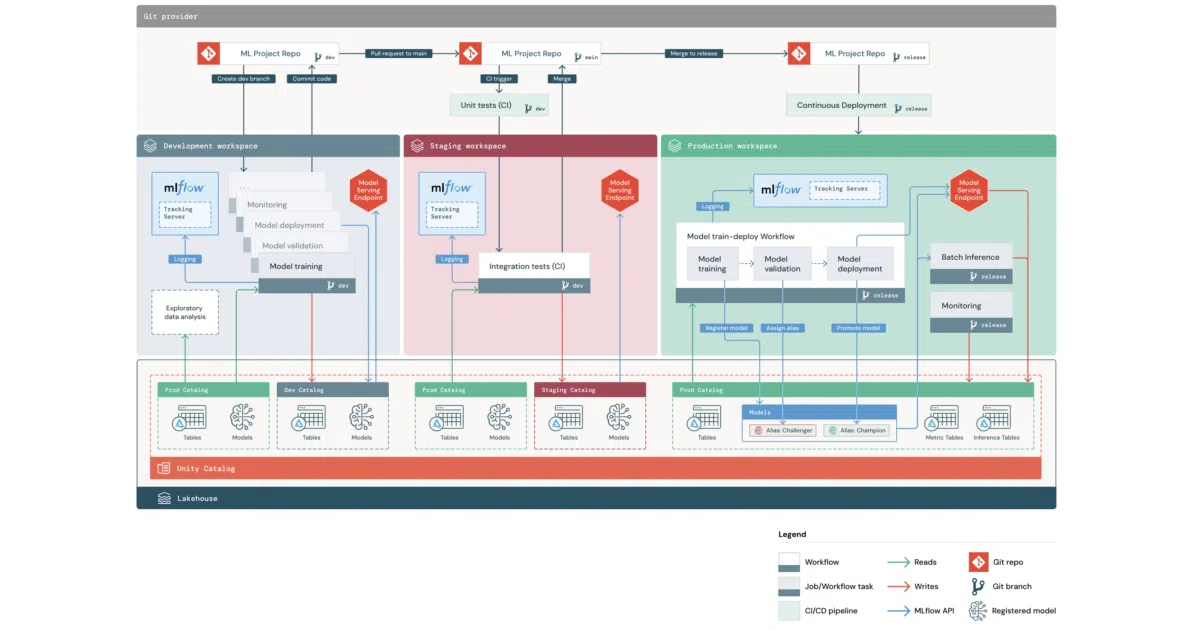
This is a Databricks CLI template (databricks bundle init mlops-stacks) that scaffolds a new ML project with three pre-wired pieces: example training and batch inference code, infrastructure definitions using Databricks asset bundles, and CI/CD workflows for GitHub Actions or Azure DevOps. The goal is letting data scientists start iterating immediately while ops handles the promotion path to staging and production workspaces.
The interesting bit
The template is deliberately modular: you can initialize just the project code (“Project_Only”), just CI/CD (“CICD_Only”), or both together. That split acknowledges the actual organizational reality where data scientists and MLEs often work in sequence, not in lockstep. It also optionally bakes in Unity Catalog model registration and Feature Store scaffolding if your estate is already there.
Key highlights
- Infrastructure-as-code via Databricks CLI bundles, meaning instance type changes for retraining jobs go through pull requests, not UI clicks
- Dev/staging/prod workspace promotion with branch-based releases (default branch for staging, separate release branch for prod)
- Optional Unity Catalog integration for model registration across environment-scoped catalogs (
dev.<schema>.<model>,prod.<schema>.<model>) - Optional Feature Store and MLflow Recipes components if you want more opinionated pipeline structure
- Supports GitHub Actions, GitHub Enterprise, Azure DevOps, and GitLab for CI/CD
Caveats
- Public preview status: Databricks asset bundles and bundle templates are both flagged as public preview, so expect churn
- Requires Databricks CLI >= v0.236.0 and some upfront workspace configuration (staging and prod host URLs, pre-existing user groups with correct permissions)
- The README trails off mid-sentence in the “Customize MLOps Stacks” section, so extending the template is left as an exercise in reading the source
Verdict
Worth a look if you’re standardizing ML projects across a Databricks estate and tired of reinventing the CI/CD wheel. Skip it if you’re not on Databricks or your “MLOps” is a single Jupyter notebook and a dream.
Frequently asked
- What is databricks/mlops-stacks?
- A project template that wires up training pipelines, batch inference, and CI/CD before you write your first line of model code.
- Is mlops-stacks open source?
- Yes — databricks/mlops-stacks is open source, released under the Apache-2.0 license.
- What language is mlops-stacks written in?
- databricks/mlops-stacks is primarily written in Go Template.
- How popular is mlops-stacks?
- databricks/mlops-stacks has 703 stars on GitHub.
- Where can I find mlops-stacks?
- databricks/mlops-stacks is on GitHub at https://github.com/databricks/mlops-stacks.