dandelin/ViLT
Vision-and-language models that skip the CNN entirely
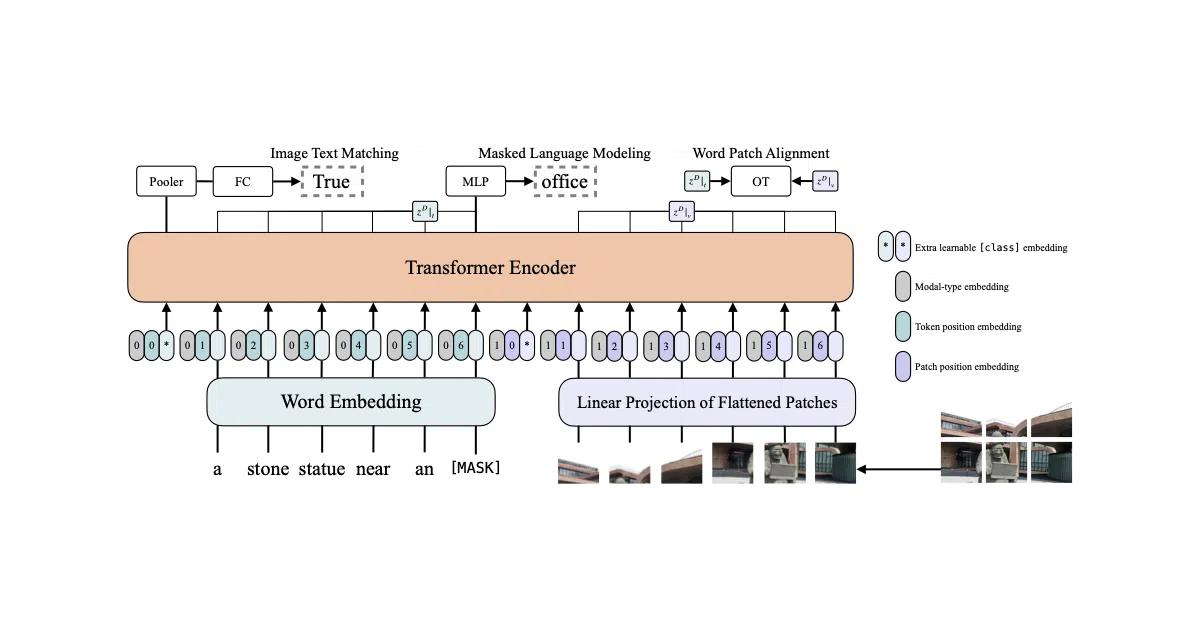
ViLT treats images as patches and text as tokens, fed into one transformer—no object detectors, no ResNet backbone.
Not currently ranked — collecting fresh signals.
star history
What it does ViLT is a vision-and-language pre-training model that strips out the usual visual feature extraction pipeline. Instead of using a CNN or region-supervised object detector to preprocess images, it patches images into flat sequences and runs them through the same transformer that handles text. The repo ships with pretrained weights, fine-tuned checkpoints for VQA and image retrieval, and two Gradio demos you can run locally.
The interesting bit The authors noticed that in prior vision-and-language models, simply extracting visual features consumed more compute than the actual multimodal reasoning. By going convolution-free, ViLT claims to be “tens of times faster” than earlier VLP models while matching or beating their downstream scores. It’s a bet that the transformer can learn visual structure from raw patches if you just give it enough data and scale.
Key highlights
- Single transformer architecture for both image patches and text tokens
- Five pretrained/fine-tuned checkpoints available via GitHub releases (VQA, NLVR2, COCO/F30K retrieval)
- Ready-to-run Gradio demos for masked language modeling visualization and VQA
- Training and evaluation pipelines documented in separate markdown files
- ICML 2021 long talk; code and weights are explicitly released for reuse
Caveats
- The “tens of times faster” claim comes from the paper abstract; no explicit benchmark numbers are shown in the README itself
- Demos pin Gradio to version 1.6.4, which is quite old and may need attention
- Dataset preparation and training details are offloaded to separate docs, so the quick-start path is inference-only
Verdict Worth a look if you’re building vision-and-language systems and want to escape the object-detector-and-CNN tax. Less useful if you need the absolute state of the art—this is a 2021 baseline with architectural conviction, not a current leaderboard topper.
Frequently asked
- What is dandelin/ViLT?
- ViLT treats images as patches and text as tokens, fed into one transformer—no object detectors, no ResNet backbone.
- Is ViLT open source?
- Yes — dandelin/ViLT is open source, released under the Apache-2.0 license.
- What language is ViLT written in?
- dandelin/ViLT is primarily written in Python.
- How popular is ViLT?
- dandelin/ViLT has 1.5k stars on GitHub.
- Where can I find ViLT?
- dandelin/ViLT is on GitHub at https://github.com/dandelin/ViLT.