boson-ai/higgs-audio
A voice engine trained on ten million hours of audio with zero fine-tuning
It exists to prove that a foundation model trained solely on unsupervised audio and text can generate expressive speech, clone voices, and improvise dialogue without task-specific fine-tuning.
Not currently ranked — collecting fresh signals.
star history
What it does Higgs Audio v2 is Boson AI’s open-source text-audio foundation model. It generates speech, clones voices from short reference clips, and produces multi-speaker dialogue in multiple languages. The model also handles emergent tasks like prosody adaptation, melodic humming, and simultaneous speech-and-music generation, all without task-specific post-training or fine-tuning according to the authors.
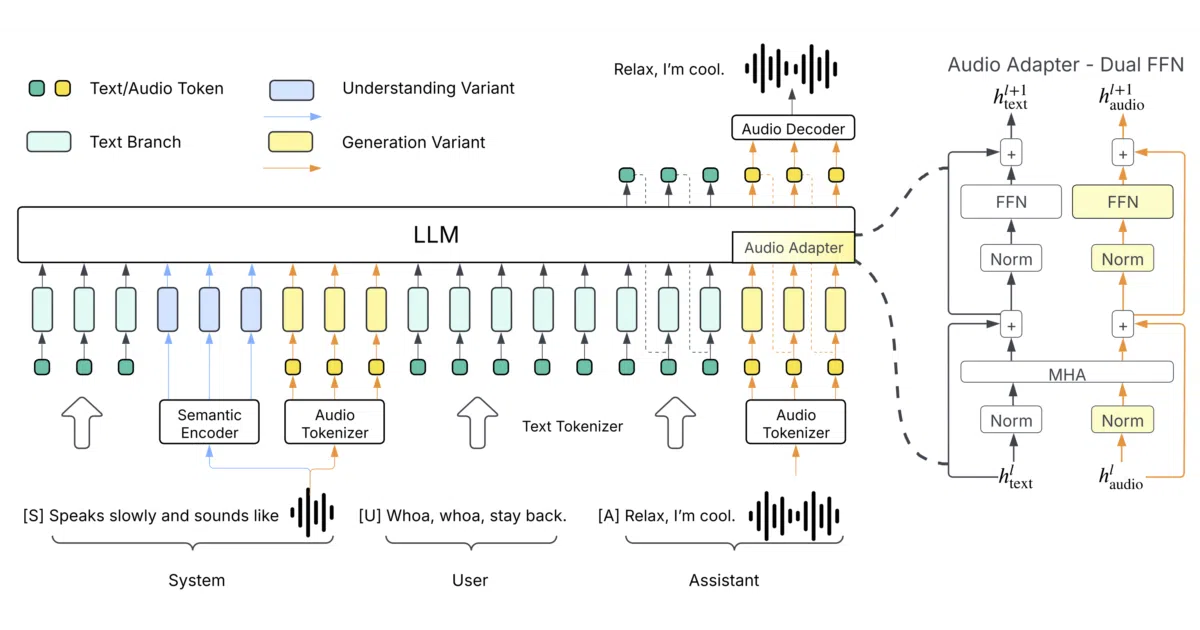
The interesting bit The model treats audio as just another language stream. It uses a custom tokenizer trained from scratch to compress both semantic and acoustic features into tokens, then feeds them through a DualFFN architecture that lets the LLM reason about sound with minimal extra compute. The training corpus—ten million hours of automatically annotated raw audio dubbed AudioVerse—was cleaned by an in-house pipeline of ASR and sound-event models.
Key highlights
- Claims state-of-the-art similarity scores on Seed-TTS Eval and ESD benchmarks, and a 75.7% win rate over
gpt-4o-mini-ttson emotional expressiveness in EmergentTTS-Eval. - Performs zero-shot voice cloning and “smart voice” casting, where the model picks appropriate speaker characteristics based on the transcript alone.
- Supports an OpenAI-compatible API server via
vLLMfor higher-throughput serving. - Requires a GPU with at least 24 GB of memory for optimal generation performance.
Caveats
- The README highlights V2.5 for production use, but the open-source checkpoint and code examples target the larger V2 base model.
- Word-error rates on Seed-TTS Eval and ESD lag behind some commercial rivals like ElevenLabs, despite leading on similarity metrics.
- The “no fine-tuning” claim applies to the V2 base model; V2.5 was aligned with GRPO on a curated Voice Bank dataset.
Verdict Worth a look if you need open-weights expressive voice synthesis or want to study multimodal LLM architectures. Skip it if you need a lightweight, CPU-friendly TTS engine; this is firmly a large-model GPU workload.
Frequently asked
- What is boson-ai/higgs-audio?
- It exists to prove that a foundation model trained solely on unsupervised audio and text can generate expressive speech, clone voices, and improvise dialogue without task-specific fine-tuning.
- Is higgs-audio open source?
- Yes — boson-ai/higgs-audio is open source, released under the Apache-2.0 license.
- What language is higgs-audio written in?
- boson-ai/higgs-audio is primarily written in Python.
- How popular is higgs-audio?
- boson-ai/higgs-audio has 8.3k stars on GitHub.
- Where can I find higgs-audio?
- boson-ai/higgs-audio is on GitHub at https://github.com/boson-ai/higgs-audio.