ace-step/ACE-Step
Generating four minutes of music in twenty seconds, with lyric control
ACE-Step is an open-source music foundation model that tries to deliver LLM-grade lyric alignment at diffusion speed.
Not currently ranked — collecting fresh signals.
star history
What it does
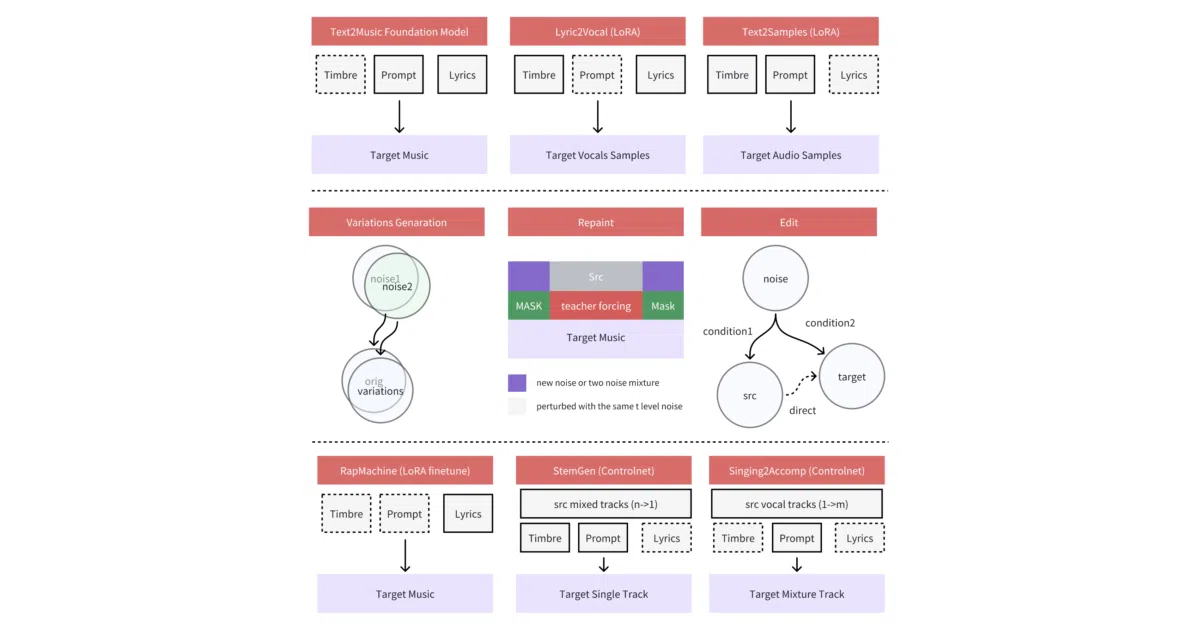
ACE-Step is an open-source music generation foundation model built around a diffusion architecture. It synthesizes instrumental and vocal music from text prompts, lyrics, or existing audio, and supports tasks like voice cloning, lyric editing, and track generation through fine-tuned LoRAs. The project also ships training code, a Gradio demo, and a ComfyUI node.
The interesting bit
Instead of picking between slow LLMs that align lyrics well and fast diffusion models that lose long-range structure, ACE-Step bolts a lightweight linear transformer and Sana’s Deep Compression AutoEncoder onto a diffusion backbone. It also uses MERT and m-hubert semantic representations during training to speed convergence, claiming 15× faster inference than LLM baselines on an A100.
Key highlights
- Generates up to four minutes of music in roughly twenty seconds on an A100, per the project’s benchmarks; an
RTX 4090can render one minute in about 1.7 seconds. - Supports 19 languages, though the README warns that less common ones may underperform due to data imbalance.
- Offers training-free variation controls, audio repainting with masks, and flow-edit lyric editing—though lyric edits must stay small to avoid distortion.
VRAMrequirements have been pushed down to 8 GB, making it viable on consumer GPUs.- Released training and LoRA training code, plus task-specific LoRAs for lyrics-to-vocal and text-to-sample generation.
Caveats
- Lyric editing is currently limited to small segments at a time; sequential edits are needed for larger changes.
- Performance on Apple Silicon is modest: a
MacBook M2 Maxtakes over 26 seconds to generate one minute of audio at 27 steps. - Several promised features—
StemGenandSinging2Accompaniment—remain on the roadmap and are not yet released.
Verdict
Worth a look for musicians, producers, and researchers who want a hackable, fast music generator with fine-grained control. If you just need a simple text-to-music button and don’t care about editing stems or lyrics, the complexity may be overkill.
Frequently asked
- What is ace-step/ACE-Step?
- ACE-Step is an open-source music foundation model that tries to deliver LLM-grade lyric alignment at diffusion speed.
- Is ACE-Step open source?
- Yes — ace-step/ACE-Step is open source, released under the Apache-2.0 license.
- What language is ACE-Step written in?
- ace-step/ACE-Step is primarily written in Python.
- How popular is ACE-Step?
- ace-step/ACE-Step has 4.6k stars on GitHub.
- Where can I find ACE-Step?
- ace-step/ACE-Step is on GitHub at https://github.com/ace-step/ACE-Step.