VertaAI/modeldb
ML experiment tracking that predates the hype cycle
An open-source system for versioning models, their ingredients, and the chaos between training and deployment.
Not currently ranked — collecting fresh signals.
star history
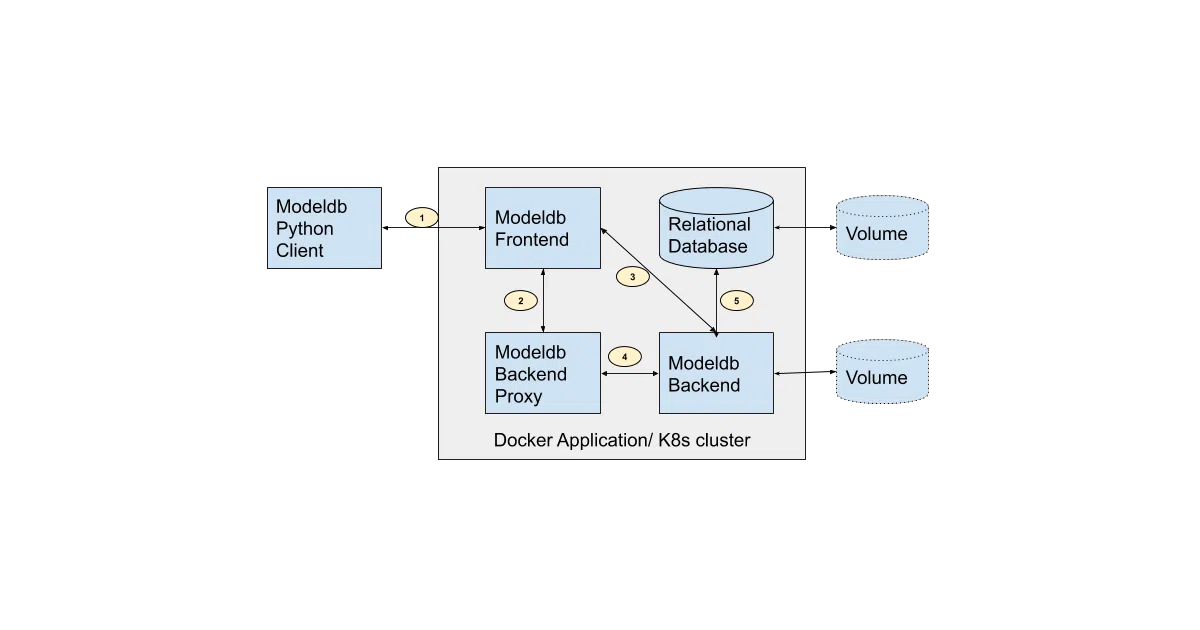
What it does ModelDB tracks machine learning experiments: hyperparameters, metrics, artifacts, and model versions. You log runs from Python or Scala, browse results in a web UI, and query history when you need to reproduce something six months later. It runs on Docker or Kubernetes with a Java backend, PostgreSQL database, and a React frontend.
The interesting bit Born at MIT CSAIL and now maintained by Verta.ai, ModelDB is old enough to have seen the MLops tooling landscape explode around it. The architecture is pleasantly explicit: a Go proxy translates gRPC between frontend and Java backend, while HTTP handles binary artifacts directly. No magic, just plumbing you can trace.
Key highlights
- Python and Scala clients; log hyperparameters and metrics with a few lines of code
- Git-like model versioning that bundles code, data, config, and environment
- Pluggable storage with Hibernate/Liquibase for database flexibility
- Helm charts and Docker Compose for deployment; AWS AMI also available
- Claims integration with TensorFlow and PyTorch, though the README doesn’t detail how
Caveats
- The “5 minutes” quickstart requires manual file creation or repo cloning first
- “Battle-tested in production” and “beautiful dashboards” are claimed but not evidenced in the README
- Commit activity and maintenance cadence are unclear from the sources
Verdict Worth evaluating if you want self-hosted experiment tracking without SaaS lock-in, especially if your stack already leans Java/Scala. Skip if you need a vibrant plugin ecosystem or want something that feels native to Python notebooks.
Frequently asked
- What is VertaAI/modeldb?
- An open-source system for versioning models, their ingredients, and the chaos between training and deployment.
- Is modeldb open source?
- Yes — VertaAI/modeldb is open source, released under the Apache-2.0 license.
- What language is modeldb written in?
- VertaAI/modeldb is primarily written in Java.
- How popular is modeldb?
- VertaAI/modeldb has 1.7k stars on GitHub.
- Where can I find modeldb?
- VertaAI/modeldb is on GitHub at https://github.com/VertaAI/modeldb.