Tiiiger/bert_score
BLEU is blind to meaning. BERTScore isn't.
A reference metric that uses contextual embeddings to judge whether your generated text actually says the same thing as the reference.
Not currently ranked — collecting fresh signals.
star history
What it does
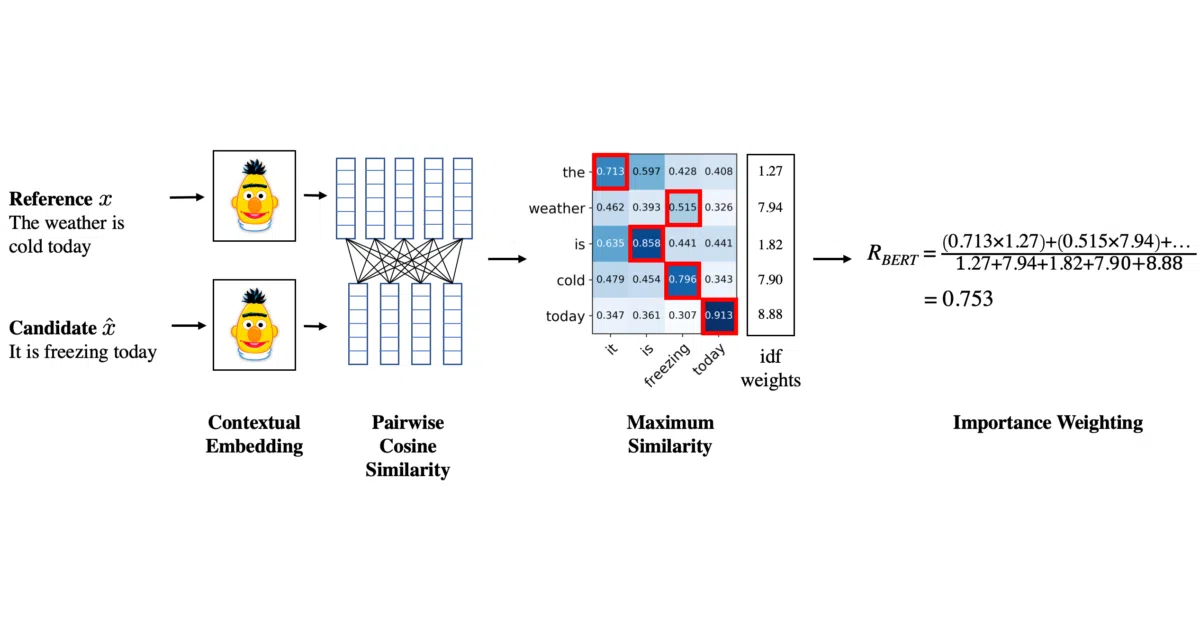
BERTScore evaluates text generation by matching words between candidate and reference sentences using cosine similarity on BERT embeddings. It outputs precision, recall, and F1 — the same familiar shapes as BLEU, but driven by semantic similarity rather than n-gram overlap. The project supports ~130 Hugging Face models and 104 languages via multilingual BERT.
The interesting bit
The authors maintain a public spreadsheet tracking which models correlate best with human judgment — currently microsoft/deberta-xlarge-mnli leads, not the default roberta-large. That kind of empirical honesty is rarer than it should be in evaluation metrics. They also provide a --rescale_with_baseline flag that stretches scores into a more human-readable range, plus a CLI tool that can visualize token-level matching heatmaps.
Key highlights
- Python API (
bert_score.score) and cachedBERTScorerobject for repeated evaluations - CLI with multi-reference support and custom model loading via
--modeland--num_layers - Rescaled baselines to widen score ranges; Google sheet tracking model-human correlations
- GPU recommended; Google Colab demo provided for the compute-constrained
- Integrated into Hugging Face’s
datasetslibrary as a built-in metric
Caveats
- Computationally expensive enough that the README explicitly warns “a GPU is usually necessary”
- Fast tokenizers produce different scores than standard ones, which is documented but easy to miss
- Default model (
roberta-large) is not the best-performing; you need to opt intodeberta-xlarge-mnlifor best correlation with human judgment
Verdict
Worth adopting if you’re still using BLEU or ROUGE for anything involving paraphrase, summarization, or translation. Skip it if you need a lightweight metric for real-time feedback loops — the BERT tax is real.
Frequently asked
- What is Tiiiger/bert_score?
- A reference metric that uses contextual embeddings to judge whether your generated text actually says the same thing as the reference.
- Is bert_score open source?
- Yes — Tiiiger/bert_score is open source, released under the MIT license.
- What language is bert_score written in?
- Tiiiger/bert_score is primarily written in Jupyter Notebook.
- How popular is bert_score?
- Tiiiger/bert_score has 1.9k stars on GitHub.
- Where can I find bert_score?
- Tiiiger/bert_score is on GitHub at https://github.com/Tiiiger/bert_score.