TheAtticusProject/cuad
A legal benchmark where even 900M-parameter models still struggle
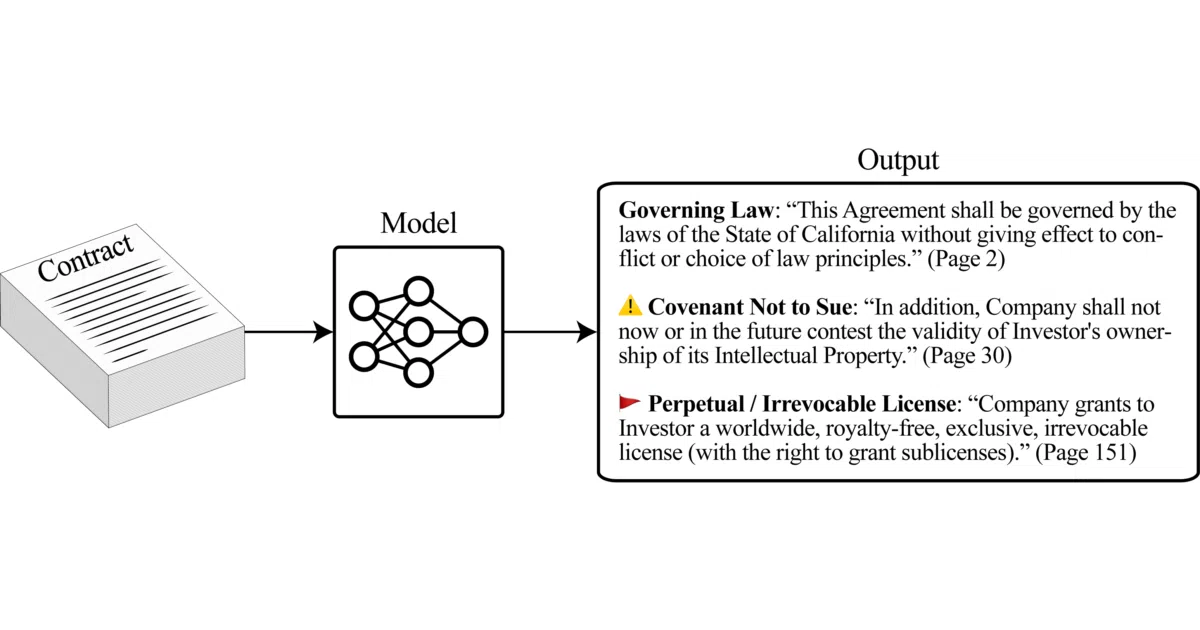
CUAD is a hand-annotated dataset for finding specific clauses in contracts—turns out "needles in a haystack" is generous.
Velocity · 7d
+0.3
★ / day
Trend
→steady
star history
What it does
CUAD provides 13,000+ expert-annotated examples for training models to extract answers from legal contracts—things like termination dates, renewal terms, and liability caps. The repo includes fine-tuning code and links to pre-trained checkpoints (RoBERTa-base through DeBERTa-xlarge).
The interesting bit
The authors are admirably blunt: Transformer performance is “nascent” and “strongly influenced” by model size and design. Even their largest model doesn’t solve this. That honesty makes CUAD genuinely useful as a research benchmark rather than a solved problem dressed up as one.
Key highlights
- Expert-annotated by actual lawyers, not crowdworkers—rare for legal NLP
- Three published checkpoints ranging from ~100M to ~900M parameters
- Several gigabytes of unlabeled contract pretraining data available separately
- Built on HuggingFace Transformers, tested with PyTorch 1.7 and Python 3.8
- NeurIPS 2021 paper with clear, non-hyped results
Caveats
- Code appears to be training/inference scripts rather than a polished library; expect to do your own plumbing
- Dependencies are pinned to older versions (Transformers 4.3/4.4, PyTorch 1.7)
Verdict
Worth a look if you’re doing legal NLP, document QA, or need a hard benchmark where SOTA still has room to breathe. Skip if you want a drop-in contract analysis product—this is research infrastructure, not a tool.