TMElyralab/MuseV
Parallel diffusion for virtual human video that never ends
MuseV is a diffusion framework that uses parallel visual-conditioned denoising to generate arbitrarily long virtual human video instead of short fixed-length clips.
Not currently ranked — collecting fresh signals.
star history
What it does
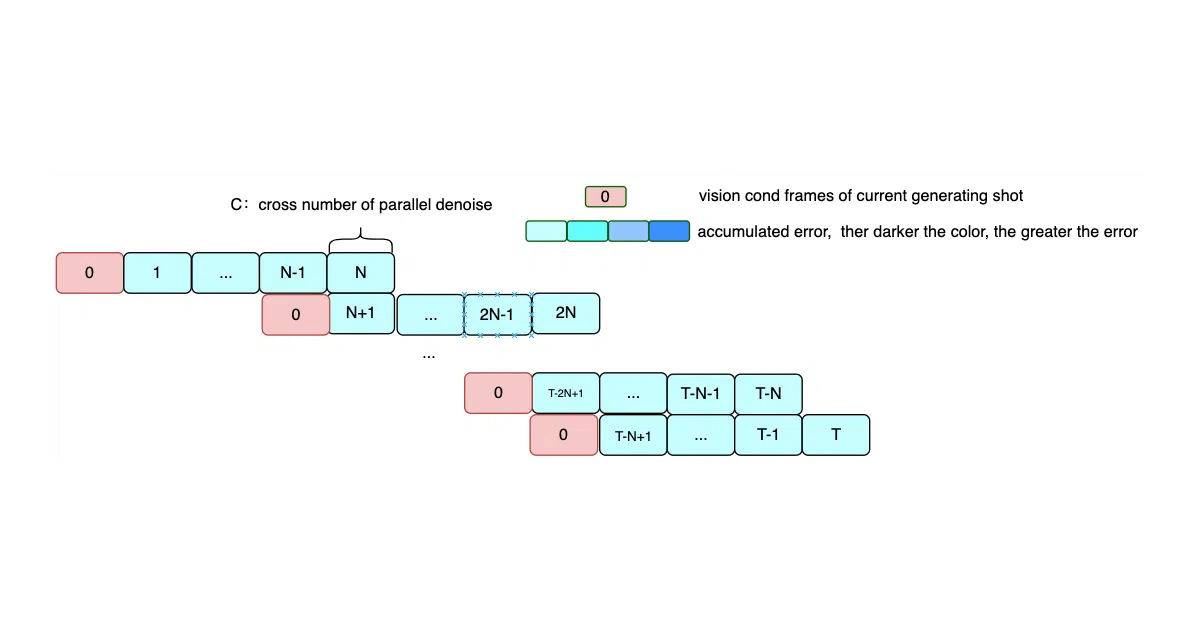
MuseV is a diffusion-based video generator focused on virtual humans. It takes images, text, or existing video and produces new footage, claiming to support infinite-length output through a Visual Conditioned Parallel Denoising scheme. It plugs into the Stable Diffusion ecosystem—base_model, LoRA, ControlNet, and various reference-image techniques like IPAdapter and ReferenceNet—so you can steer characters and styles with familiar tooling.
The interesting bit
The parallel denoising approach is the hook: instead of the usual sequential or fixed-window generation, the model denoises against visual conditions in a way that lets it extend video length without hard cutoffs. The team also treats MuseV as one leg of a tripod, alongside their separate MuseTalk lip-sync and MusePose pose-control projects, for an end-to-end virtual human pipeline.
Key highlights
- Claims infinite-length generation via a novel parallel denoising approach, with examples showing 1–2 minute outputs.
- Compatible with Stable Diffusion add-ons:
LoRA,ControlNet,IPAdapter,ReferenceNet, andIPAdapterFaceID. - Supports multiple input modes: Image2Video, Text2Image2Video, and Video2Video.
- GPU memory starts around 8 GB for the base motion module and roughly 12 GB for the reference-network variant at 512×512.
- Training code and a technical report are listed as “coming soon”; the current release is inference-focused.
Caveats
- The README warns that installation outside Docker may be troublesome; conda and pip setups are noted as potentially problematic.
- A naming bug in the
musev_referencenet_poseconfiguration requires using a specific corrected command string. - The motion model was trained on relatively small datasets—about 60K video-text pairs from tiny UCF101 and WebVid subsets—so generalization limits are unclear.
Verdict
Worth a look if you are building virtual human pipelines and want a modular, SD-compatible video generator with a plausible mechanism for long-form output. Skip it if you need battle-tested training code or guaranteed production stability today.
Frequently asked
- What is TMElyralab/MuseV?
- MuseV is a diffusion framework that uses parallel visual-conditioned denoising to generate arbitrarily long virtual human video instead of short fixed-length clips.
- Is MuseV open source?
- Yes — TMElyralab/MuseV is an open-source project tracked on heatdrop.
- What language is MuseV written in?
- TMElyralab/MuseV is primarily written in Python.
- How popular is MuseV?
- TMElyralab/MuseV has 2.8k stars on GitHub.
- Where can I find MuseV?
- TMElyralab/MuseV is on GitHub at https://github.com/TMElyralab/MuseV.