OpenMOSS/MOSS-TTS
One repo, five models: an open-source speech family
MOSS-TTS splits speech synthesis into five specialized models—narration, dialogue, real-time streaming, voice design, and sound effects—instead of forcing one architecture to do it all.
Velocity · 7d
+20
★ / day
Trend
↗accelerating
star history
What it does
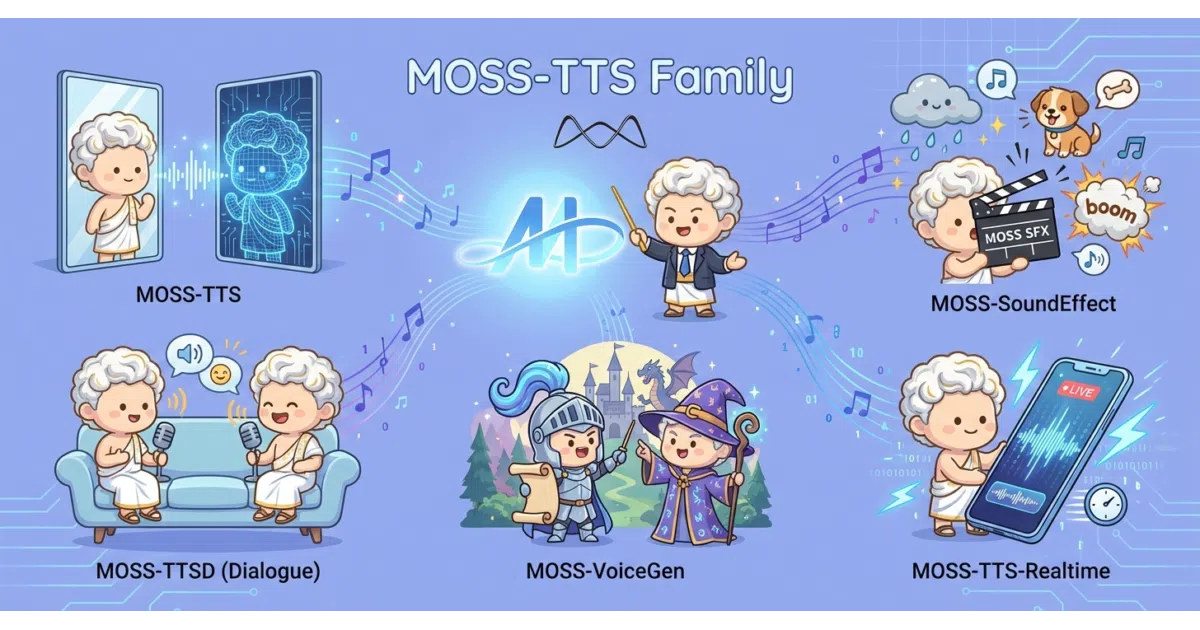
MOSS-TTS is a collection of five production-ready audio models that cover the full speech pipeline. The flagship MOSS-TTS handles long-form narration and zero-shot voice cloning with phoneme-level control; MOSS-TTSD generates multi-speaker dialogues; MOSS-VoiceGenerator designs new voices from text prompts alone; MOSS-TTS-Realtime targets low-latency voice agents with incremental synthesis; and MOSS-SoundEffect generates environmental audio and soundscapes. A separate MOSS-TTS-Nano variant squeezes multilingual streaming onto four CPU cores.
The interesting bit
The project treats TTS as infrastructure, not a demo. It exposes two distinct architectures—MossTTSDelay for stable long-context work and MossTTSLocal for lightweight streaming—and can run entirely without PyTorch via llama.cpp and ONNX, allowing an 8B model to fit on an 8GB GPU.
Key highlights
- Five specialized models instead of a single generalist: TTS, dialogue (
TTSD), voice design (VoiceGenerator), real-time streaming (Realtime), and sound effects (SoundEffect). MOSS-TTS-Realtimeclaims a 180 ms time-to-first-byte and incremental synthesis for multi-turn voice agents.MOSS-TTS-Nanoruns ~100M parameters and streams 48 kHz stereo audio on four CPU cores.- A PyTorch-free inference path using
llama.cppand ONNX Runtime, with an SGLang backend that reportedly pushesMossTTSDelaythroughput up by roughly 3×. - Fine-grained control over duration, Pinyin, phonemes, and explicit pauses via markup like
[pause X.Ys]in the flagship model.
Verdict
Developers building voice agents, audiobook pipelines, or content-generation tools should look here—especially if you need to deploy offline or on modest hardware. If you just need a quick, single-speaker TTS snippet and don’t care about latency or long-form stability, the complexity of a five-model family might be overkill.
Frequently asked
- What is OpenMOSS/MOSS-TTS?
- MOSS-TTS splits speech synthesis into five specialized models—narration, dialogue, real-time streaming, voice design, and sound effects—instead of forcing one architecture to do it all.
- Is MOSS-TTS open source?
- Yes — OpenMOSS/MOSS-TTS is open source, released under the Apache-2.0 license.
- What language is MOSS-TTS written in?
- OpenMOSS/MOSS-TTS is primarily written in Python.
- How popular is MOSS-TTS?
- OpenMOSS/MOSS-TTS has 3.9k stars on GitHub and is currently accelerating.
- Where can I find MOSS-TTS?
- OpenMOSS/MOSS-TTS is on GitHub at https://github.com/OpenMOSS/MOSS-TTS.