OFA-Sys/ONE-PEACE
A 4B-parameter model that hears, sees, and reads—without borrowing from CLIP or Whisper
ONE-PEACE trains vision, audio, and language representations from scratch, then lets you retrieve images by humming or describing them.
Not currently ranked — collecting fresh signals.
star history
What it does
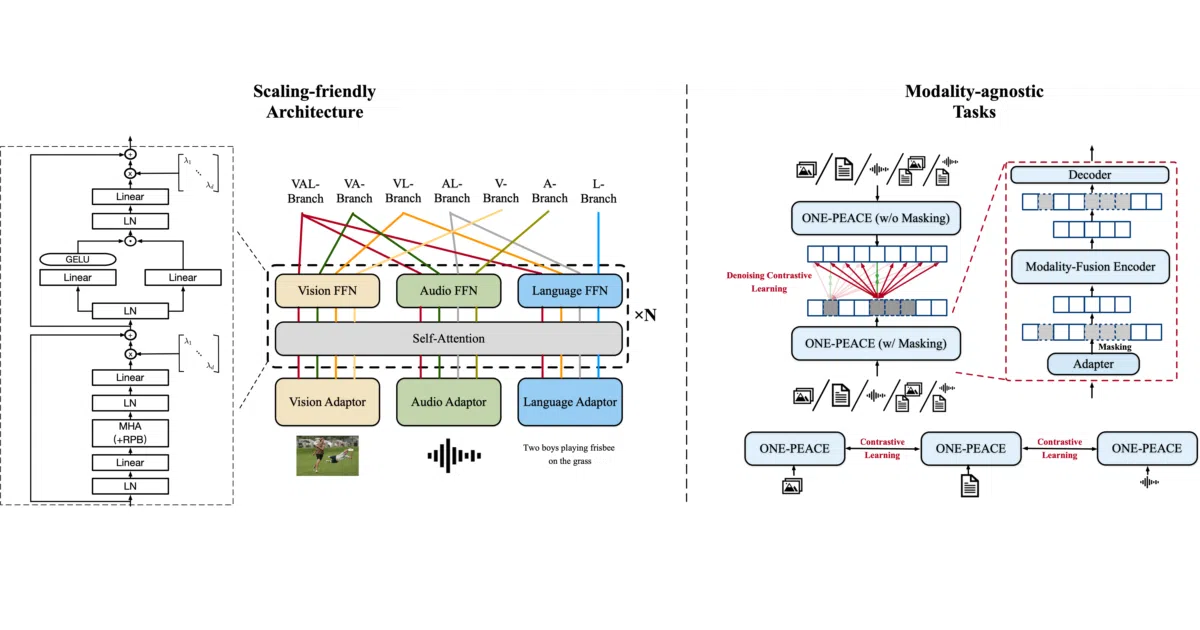
ONE-PEACE is a 4-billion-parameter transformer that ingests images, audio, and text through a single architecture. It doesn’t bootstrap from existing vision or language pretrained models; everything is trained jointly from random initialization. The project ships pretrained checkpoints, fine-tuning scripts for vision/audio/language tasks, and a Hugging Face demo where you can query images with arbitrary modality combinations—audio alone, audio plus text, even audio plus image plus text.
The interesting bit
The model exhibits emergent zero-shot cross-modal retrieval: it can align modalities that were never paired in training data. The architecture is designed to be “scaling-friendly” and modality-agnostic, with the explicit goal of expanding to “unlimited modalities.” Think of it as a universal embedding space where a cow’s moo, a photo of a cow, and the word “cow” all land near each other—without anyone explicitly supervising that triangle during training.
Key highlights
- Trained from scratch (no CLIP, BERT, or Whisper initialization)
- 4B parameters, 40 layers, 1536 hidden size; disassemblable into task-specific branches (e.g., 1.5B vision-only)
- Strong reported results: 89.8% ImageNet-1K, 91.8% zero-shot ESC-50 audio, 84.1/65.4 I2T/T2I on COCO
- APIs for multimodal embedding extraction, visual grounding, and audio classification
- Live demo supports audio-to-image, audio+text-to-image, and audio+image+text-to-image retrieval
Caveats
- Requires significant GPU resources (CUDA 11.6 recommended, optional Apex/XFormers/FlashAttention for training)
- The “unlimited modalities” claim is aspirational; only vision, audio, and language are demonstrated
- Some code snippets in the README appear truncated (audio classification example cuts off mid-line)
Verdict
Worth exploring if you’re building cross-modal search or need a unified embedding model that wasn’t shaped by existing pretrained biases. Skip it if you just need a quick CLIP drop-in; this is heavier, hungrier, and more research-oriented.
Frequently asked
- What is OFA-Sys/ONE-PEACE?
- ONE-PEACE trains vision, audio, and language representations from scratch, then lets you retrieve images by humming or describing them.
- Is ONE-PEACE open source?
- Yes — OFA-Sys/ONE-PEACE is open source, released under the Apache-2.0 license.
- What language is ONE-PEACE written in?
- OFA-Sys/ONE-PEACE is primarily written in Python.
- How popular is ONE-PEACE?
- OFA-Sys/ONE-PEACE has 1.1k stars on GitHub.
- Where can I find ONE-PEACE?
- OFA-Sys/ONE-PEACE is on GitHub at https://github.com/OFA-Sys/ONE-PEACE.