MeiGen-AI/MultiTalk
AI video generation learns to lip-sync group conversations
MultiTalk generates multi-person talking-head videos from audio, handling overlapping speech and prompt-directed interactions.
Not currently ranked — collecting fresh signals.
star history
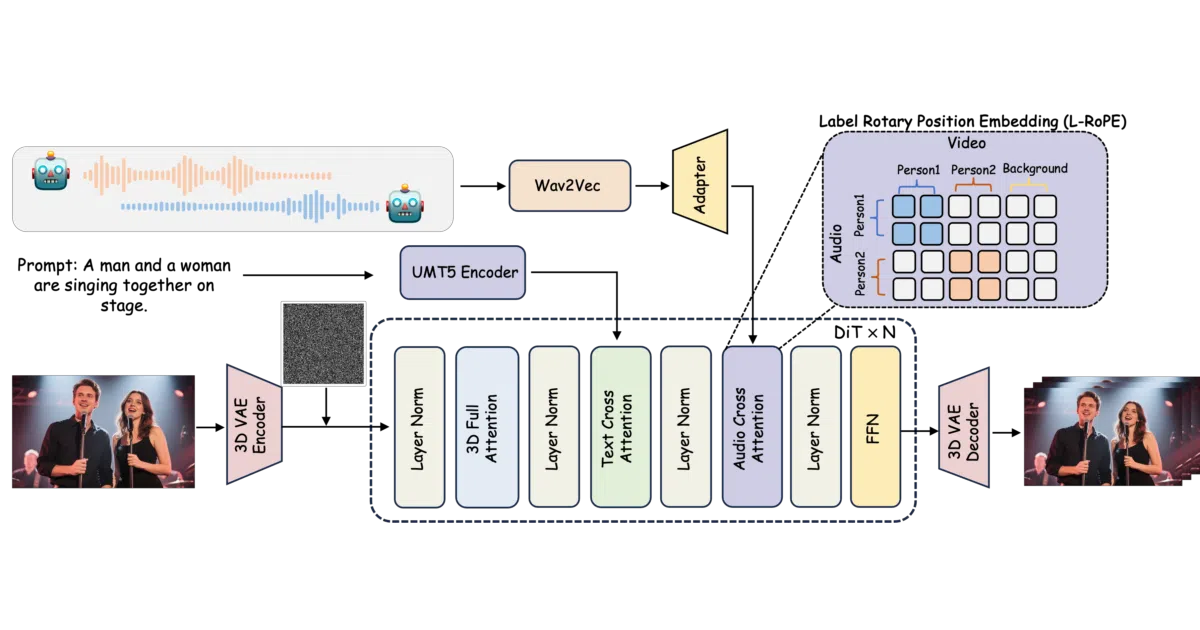
What it does MultiTalk takes multi-stream audio, a reference image, and a text prompt, then generates a video of people having a conversation with lip motions matched to the audio. It handles single-person clips, multi-person dialogues, singing, and even cartoon characters. Output is supported at 480p or 720p, up to 15 seconds long.
The interesting bit The hard part isn’t making one face move to audio — it’s keeping multiple speakers coherent when their voices overlap. MultiTalk builds on the Wan2.1-I2V-14B video diffusion model with custom audio-conditioning weights, and the community has already squeezed it down to run on 8 GB VRAM hardware.
Key highlights
- Multi-stream audio input: handles conversations with several overlapping speakers
- Prompt-based interaction control: direct who looks at whom or what they do
- Built-in TTS via Kokoro-82M for text-to-video pipelines
- Acceleration options: TeaCache (~2–3× speedup), INT8 quantization, SageAttention2.2, and FusionX/lightx2v LoRA for 4–8 step inference
- Low-VRAM path: 480p generation on a single RTX 4090; community fork hits 8 GB
- Gradio demo, ComfyUI integration, and Replicate deployment all exist
Caveats
- 720p inference requires multiple GPUs; current open-source code only ships 480p
- Setup involves manual symlinking or copying safetensors into the Wan2.1 directory
- Todo list shows LCM distillation, sparse attention, and a 1.3B model are still pending
Verdict Worth a look if you’re building AI avatars, dubbing tools, or synthetic media pipelines. Skip it if you need turnkey deployment or are GPU-poor and impatient — the setup is fiddly and the sweet spot still wants an RTX 4090 or better.
Frequently asked
- What is MeiGen-AI/MultiTalk?
- MultiTalk generates multi-person talking-head videos from audio, handling overlapping speech and prompt-directed interactions.
- Is MultiTalk open source?
- Yes — MeiGen-AI/MultiTalk is open source, released under the Apache-2.0 license.
- What language is MultiTalk written in?
- MeiGen-AI/MultiTalk is primarily written in Python.
- How popular is MultiTalk?
- MeiGen-AI/MultiTalk has 3k stars on GitHub.
- Where can I find MultiTalk?
- MeiGen-AI/MultiTalk is on GitHub at https://github.com/MeiGen-AI/MultiTalk.