MeiGen-AI/InfiniteTalk
Audio-driven dubbing that animates your whole body, not just your lips
Most dubbing tools move the lips and call it a day; this one syncs the entire body to an audio track for unlimited-length output.
Velocity · 7d
+6.9
★ / day
Trend
↘cooling
star history
What it does
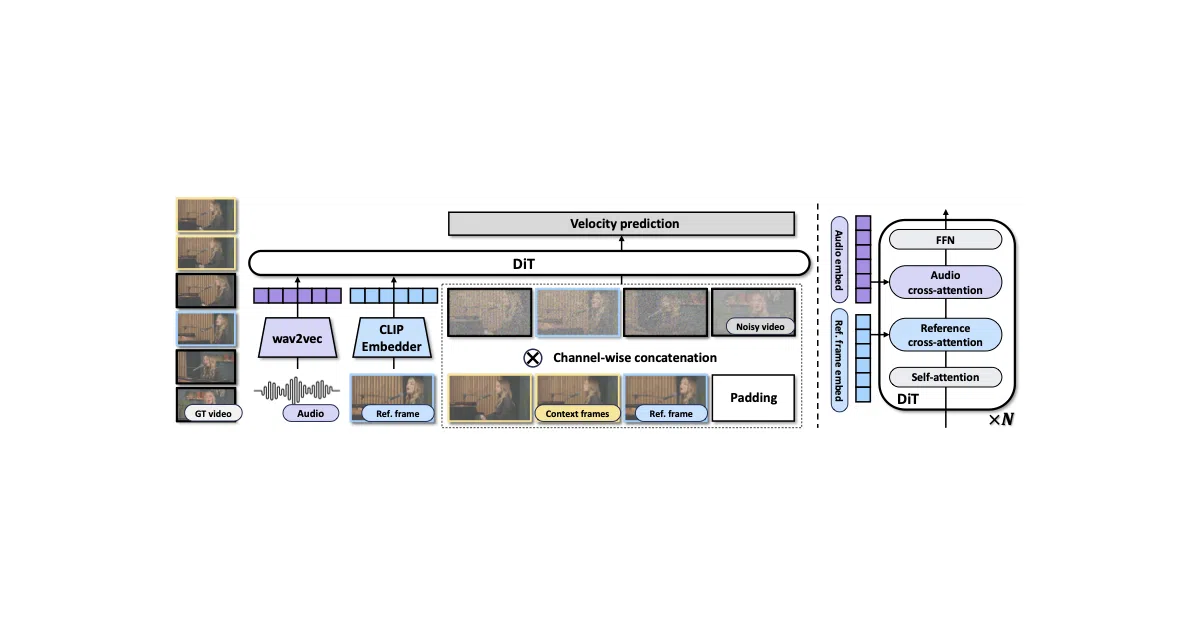
InfiniteTalk is an audio-conditioned video generation model built atop Wan2.1-I2V-14B-480P. Feed it an audio track plus either a source video or a still image, and it outputs a talking-head video where the subject’s lips, head pose, body posture, and facial expressions all follow the sound. The system is explicitly designed for unlimited-duration generation with consistent identity preservation.
The interesting bit
The project treats dubbing as sparse-frame video generation rather than a mouth-shape swap. By conditioning on audio through a chinese-wav2vec2-base encoder and generating motion holistically, it claims to reduce the hand and body distortions that plague earlier methods like MultiTalk. The trade-off is visible color shift and weakened identity preservation once clips exceed roughly one minute.
Key highlights
- Synchronizes lips, head, body, and expressions simultaneously from an audio track
- Supports both video-to-video redubbing and image-to-video avatar creation
- Generates unlimited-length output via a streaming inference mode
- Ships with
GradioandComfyUIinterfaces, plusint8quantization andTeaCachefor low-VRAM inference - Community integrations already exist in
Wan2GPand Kijai’sComfyUI-WanVideoWrapper
Caveats
- Color shifts and reduced identity preservation become noticeable beyond one minute, especially with
FusionX LoRAenabled - Camera movement in video-to-video mode is approximated rather than identical to the source;
SDEditimproves accuracy but is best suited for short clips - Long-video camera control and sparse-attention acceleration remain on the project’s todo list
Verdict
Worth a look if you need long-form audio-driven avatars or automated dubbing with whole-body motion. Skip it if you require identical camera fidelity or consistent identity and color fidelity beyond one minute.
Frequently asked
- What is MeiGen-AI/InfiniteTalk?
- Most dubbing tools move the lips and call it a day; this one syncs the entire body to an audio track for unlimited-length output.
- Is InfiniteTalk open source?
- Yes — MeiGen-AI/InfiniteTalk is open source, released under the Apache-2.0 license.
- What language is InfiniteTalk written in?
- MeiGen-AI/InfiniteTalk is primarily written in Python.
- How popular is InfiniteTalk?
- MeiGen-AI/InfiniteTalk has 7.5k stars on GitHub and is currently cooling off.
- Where can I find InfiniteTalk?
- MeiGen-AI/InfiniteTalk is on GitHub at https://github.com/MeiGen-AI/InfiniteTalk.