FunAudioLLM/Fun-ASR
A speech model that understands 26 Chinese accents and song lyrics
Fun-ASR exists to transcribe 31 languages, 26 Chinese regional accents, and even song lyrics at production speed by running the vLLM engine underneath an 800M-parameter audio model.
Not currently ranked — collecting fresh signals.
star history
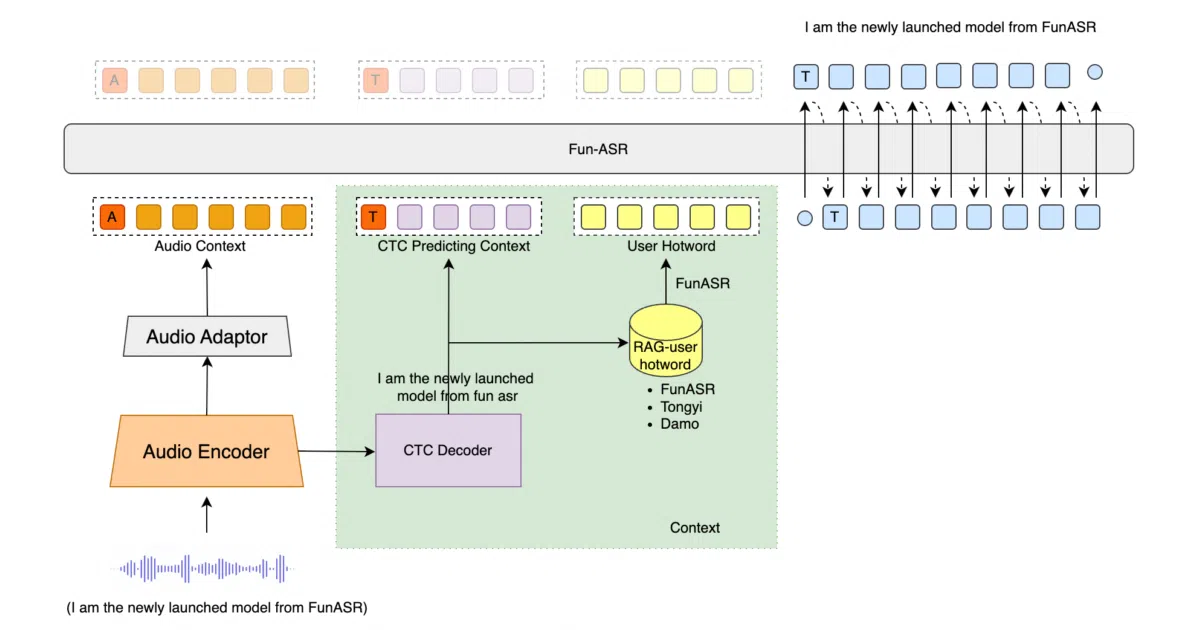
What it does Fun-ASR is an end-to-end speech recognition model from Alibaba’s Tongyi Lab. At 800 million parameters and trained on tens of millions of hours of audio, it converts speech to text across 31 languages, with particular depth for Chinese dialects, regional accents, and noisy far-field environments. It also handles speaker diarization, timestamps, custom hotwords, and lyric recognition under musical background noise.
The interesting bit Rather than building a bespoke serving stack, the project plugs directly into the vLLM inference engine to handle both real-time WebSocket streams and offline batch transcription. The README shows a roughly 20× throughput gain over PyTorch native inference on a 192-minute test file, with no meaningful hit to character error rate.
Key highlights
- Two-model split: the Nano variant covers Chinese (7 dialects plus 26 regional accents), English, and Japanese; the MLT-Nano variant covers the remaining 28 languages.
- vLLM backend delivers 393.9× RTFx on batch transcription, versus 19.6× for PyTorch native, on identical 192-minute test audio.
- Supports speaker diarization, word-level timestamps, custom hotwords, and lyric extraction from music.
- Claims 93% recognition accuracy in far-field, high-noise scenarios such as conference rooms and industrial sites.
- Provides both a streaming WebSocket service and a chunked streaming SDK for real-time subtitles.
Caveats
- Loading the model requires
trust_remote_code=Trueand a localmodel.py, so you are explicitly running unaudited remote code. - Speaker diarization currently depends on installing the separate FunASR toolkit from source, not just this repository.
- Language coverage is split across two distinct 800M checkpoints, so “31 languages” does not mean one single model handles them all.
Verdict Worth evaluating if you need production-grade Chinese ASR with dialect support, real-time transcription, or lyric extraction. Skip it if you want a single multilingual checkpoint or a drop-in replacement that does not require trusting remote model code.
Frequently asked
- What is FunAudioLLM/Fun-ASR?
- Fun-ASR exists to transcribe 31 languages, 26 Chinese regional accents, and even song lyrics at production speed by running the vLLM engine underneath an 800M-parameter audio model.
- Is Fun-ASR open source?
- Yes — FunAudioLLM/Fun-ASR is open source, released under the Apache-2.0 license.
- What language is Fun-ASR written in?
- FunAudioLLM/Fun-ASR is primarily written in C.
- How popular is Fun-ASR?
- FunAudioLLM/Fun-ASR has 1.4k stars on GitHub.
- Where can I find Fun-ASR?
- FunAudioLLM/Fun-ASR is on GitHub at https://github.com/FunAudioLLM/Fun-ASR.