CalculatedContent/WeightWatcher
X-ray your neural network without touching the data
WeightWatcher diagnoses deep learning models using random matrix theory—no training or test data required.
Not currently ranked — collecting fresh signals.
star history
What it does
WeightWatcher is a Python diagnostic tool that inspects trained PyTorch and Keras models by analyzing the eigenvalue distributions of weight matrices. It generates per-layer metrics and summary statistics to flag over-trained or under-trained layers, predict test accuracy, and spot problems before compression or fine-tuning. You feed it a model; it returns a pandas DataFrame and a dictionary of generalization metrics like alpha, stable_rank, and log_spectral_norm.
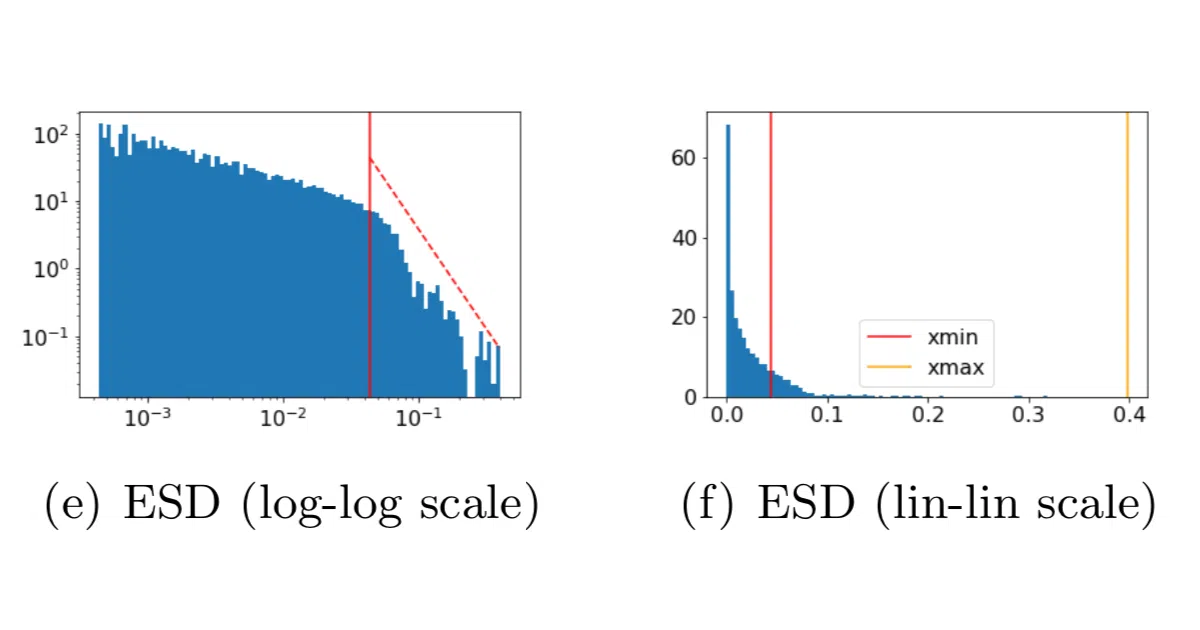
The interesting bit
The tool is built on a theory the authors call Heavy-Tailed Self-Regularization (HT-SR), drawing from random matrix theory and statistical mechanics. The core insight: well-trained layers have eigenvalue spectra that follow power laws, while poorly trained ones look closer to random noise. The README claims they can rank VGG models by ImageNet accuracy without ever peeking at the test set—though you’ll have to run the notebooks yourself to verify that on your hardware.
Key highlights
- Zero-data diagnosis: analyzes models without training or test data access
- Per-layer spectral analysis with power-law fits and Marchenko-Pastur bulk comparisons
- Summary metrics (
alpha_weighted,log_alpha_norm, etc.) for cross-model comparison - Experimental PEFT/LoRA support for analyzing fine-tuned adapters
- New in v0.8.0: “correlation trap” detection via randomized diagnostics
- Published in Nature; active research with recent NeurIPS talks and a monograph
Caveats
- Power-law fits require at least 50 eigenvalues per layer; small layers get skipped
- PEFT/LoRA support is experimental and ignores biases, requires matching layer names and formats
- The examples folder in-repo is “quite old”; current demos live in a separate repo
Verdict
Worth a look if you’re doing model selection, compression, or debugging mysterious accuracy drops—especially when you can’t share or access the original dataset. Less useful if you already have abundant validation data and just want standard metrics.
Frequently asked
- What is CalculatedContent/WeightWatcher?
- WeightWatcher diagnoses deep learning models using random matrix theory—no training or test data required.
- Is WeightWatcher open source?
- Yes — CalculatedContent/WeightWatcher is open source, released under the Apache-2.0 license.
- What language is WeightWatcher written in?
- CalculatedContent/WeightWatcher is primarily written in Python.
- How popular is WeightWatcher?
- CalculatedContent/WeightWatcher has 1.8k stars on GitHub.
- Where can I find WeightWatcher?
- CalculatedContent/WeightWatcher is on GitHub at https://github.com/CalculatedContent/WeightWatcher.